
- В настоящее время наш холодильник "Марвин" может сказать нам через Twitter, что он чувствует себя совершенно...
- Какие книги написал автор Дуглас Адамс?
- Как вы могли бы использовать структурированные данные из викиданных для своего собственного проекта?

Когда я начал использовать компьютеры, я никогда не задумывался о том, могут ли они помочь мне делать что-то и как это, в свою очередь, улучшит мою жизнь. Я автоматически предположил, что мы изобрели инструменты, машины, устройства, телефоны, компьютеры и так далее, потому что мы хотели сделать нашу жизнь лучше и меньше думать о утомительных задачах, делая сложные и особенно сложные задачи более легкими и удобными в использовании.
В конце 90-х я не только узнал, но и испытал, что компьютеры подключены. Была такая вещь, как Интернет, в основном рекламируемая в форме WWW, всемирной паутины: миллиарды документов, более или менее связанных друг с другом. В основном оштукатурены яркими анимациями о том, что это место находится в стадии строительства. И тег <marquee> заставил нас чувствовать себя так же важно, как последние новости или тикер на фондовом рынке.
Ах да, старый добрый интернет. В начале довольно статичный и в основном текстовый, но он стал более богатым, более универсальным, динамичным и включал в себя изображения, аудио и видео. Помимо статических сайтов, мы создали веб-приложения, API-интерфейсы и сделали Интернет местом, где можно взаимодействовать друг с другом и с машинами.
В настоящее время наш холодильник "Марвин" может сказать нам через Twitter, что он чувствует себя совершенно пустым и грустным
В детстве я читал тонны книг, в основном художественную, конечно, но помню, что довольно часто посещал нашу библиотеку в деревне и брал книги, объясняющие мне мир. Но я потреблял так много, что не мог хранить всю информацию в своей голове, сейчас я не настолько осведомлен, как десятилетия назад. Я помню фрагменты, но, что более важно, я обычно помню, где мне нужно искать фактические данные, чтобы заполнить пробелы.
Я вырос с Google с самого начала. И хотя старые и поддерживаемые вручную каталоги и каталоги были хорошей отправной точкой для изучения цифровой вселенной, поисковые машины облегчили мою жизнь. Теперь мне даже не нужно было больше держать в голове индекс и график фрагментов информации, я мог перейти к навыку правильных вопросов.
Но есть несколько проблем с большинством поисковых систем общего назначения. Самый простой способ создать индекс - это просканировать Интернет, получить полный текст каждой обнаруженной страницы и связать его с ключевыми словами. Позже, когда кто-то ищет это ключевое слово, он получит огромный список результатов. Алгоритмы стали умнее, чем лучше вы сможете сформулировать свой запрос, тем более актуальным и сжатым будет список.
Но если вы думаете об этом, вы уже можете задавать очень конкретные вопросы, и большинство поисковых систем действительно не смогут «получить это» с самого начала.
Какие книги написал автор Дуглас Адамс?
Если бы вы попробовали это, может быть, 10 или даже 5 лет назад, и вам повезло, то какой-то результат на первой странице привел бы вас к статье о его публикациях. Если вы не используете Google или WolframAlpha, ситуация все еще весьма разочаровывает.
Сегодня я очень впечатлен тем, как это работает:
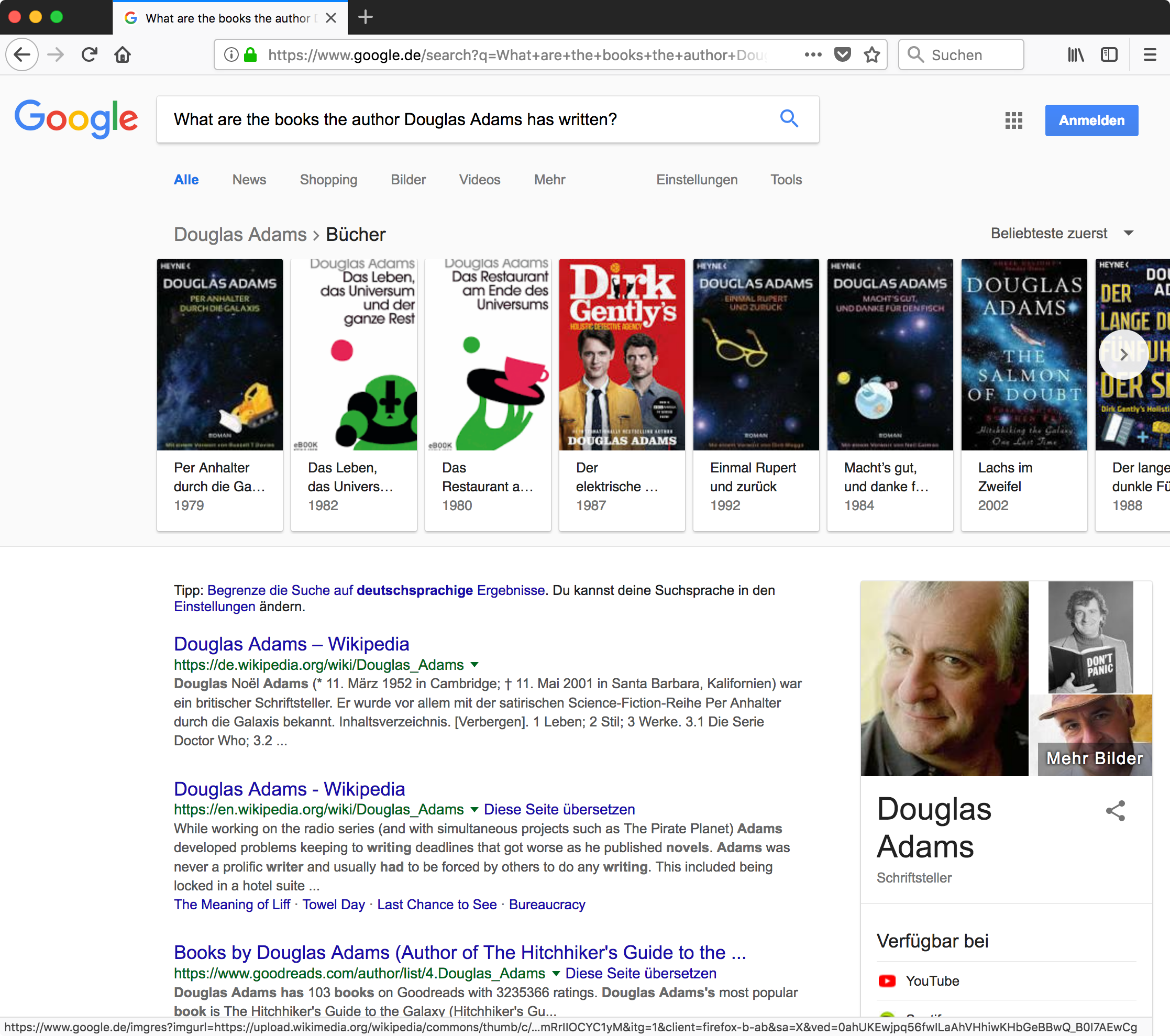
Как вы также можете видеть, первые два органических результата относятся к автору в Википедии, только третий близок к тому, о чем я спрашивал. Но верхняя планка с обложками книг ее покачивает!
И здесь я сделаю смелое заявление: предоставить вам такую конкретную и релевантную контексту информацию невозможно только на основе некоторого индекса полнотекстового поиска; Я считаю, что это было обусловлено структурированными данными (и, возможно, хранится в базе данных графа ... возможно)
Моя внутренняя программа QuickCheck сузила ее до « книг Дугласа Адамса», но это не главное (хотя анализ ввода окна поиска, вероятно, сам по себе является хорошим приключением).
Мы можем далее разложить наш запрос и понять, что он состоит из кортежа: «Дуглас Адамс» и «Книги» . Первый описывает имя человека, второй описывает тип объекта, и, очевидно, мы хотим найти связь между этим человеком и книгами, которые он написал. Поскольку люди редко упоминают, какие книги они прочитали, анализатор запросов уже может сделать обоснованное предположение и указать в качестве типа отношения «написал» (также «опубликовал» может сработать).
Или выражается на языке псевдопросмотра и очень упрощенно:
ВЫБРАТЬ * ИЗ книг, ГДЕ author = "Дуглас Адамс"
Конечно, сначала вам нужно будет определить сущность автора / персоны из вашей базы данных:
ВЫБЕРИТЕ идентификатор от людей, ГДЕ name = "Дуглас Адамс"
И тогда вы понимаете, что ваша таблица / база данных людей может иметь несколько записей, и вы пытаетесь фильтровать по профессии или хобби. Возможно, вы оценили их по популярности и просто займете самую высокую позицию. Другой вариант - разрешить полный запрос для каждого человека и проверить, какая из них написала больше всего книг (если вообще есть), и использовать эту.
Каким бы ни был подход, вам нужно хранить данные структурированным образом. И если вы хотите создать поисковую систему, базу данных знаний или любое другое приложение, запрашивающее и представляющее такую информацию (но не хранящее всю эту информацию), вам нужно полагаться на другие источники, предоставляя их в удобном для компьютера виде.

Идея структурированных данных и семантической паутины не нова. И если вы использовали какое-либо программное обеспечение для ведения блогов, то вы также использовали некоторые аспекты структурирования: категории и теги.
В зависимости от ваших потребностей вы даже ввели свои собственные таксономии для описания и дифференциации своих статей. В качестве примера: вы рецензент фильмов и классифицируете свои обзоры в зависимости от настроения, целевой аудитории и жанров; Все эти измерения помогают вам описывать ваши данные, делают их более доступными для обнаружения, поддерживают потребляющие системы и прямо или косвенно предоставляют вашим читателям больше контекста и метаданных, обычно более быстрым и простым способом, чтобы они могли решить, хотят ли они погружаться. глубже в свой блог или заглянуть куда-нибудь еще.
Предварительные просмотры статей / открытки в Facebook и Twitter также основаны на структурированных данных. Когда вы просматриваете исходный код некоторых HTML-страниц, вы можете обнаружить некоторые интересные метатеги с именами или свойствами, такими как « og: title », « twitter: creator » или « article: author ». Они используются, чтобы заполнить части предварительного просмотра. И, честно говоря, вы, скорее всего, нажмете на сообщение в блоге, когда у него хорошее изображение обложки и строка описания, не так ли?

Нам потребовались годы, чтобы собрать больше данных или использовать весь потенциал структурированных данных, но в настоящее время эта концепция является основой Интернета. Даже с ИИ на подъеме машины могут лучше всего выполнять свою работу, если они могут структурировать данные.
Я думаю, что искусство состоит в том, чтобы отображать контент приятным, понятным для человека способом и ненавязчиво обогащать его семантической информацией, потребляемой машиной. Это сделано для того, чтобы мы могли создавать интерфейсы и приложения, которые могли бы понять все данные, а затем визуализировать их другим и более доступным способом.
Если вы хотите посмотреть, как могут выглядеть структурированные данные, перейдите к wikidata:
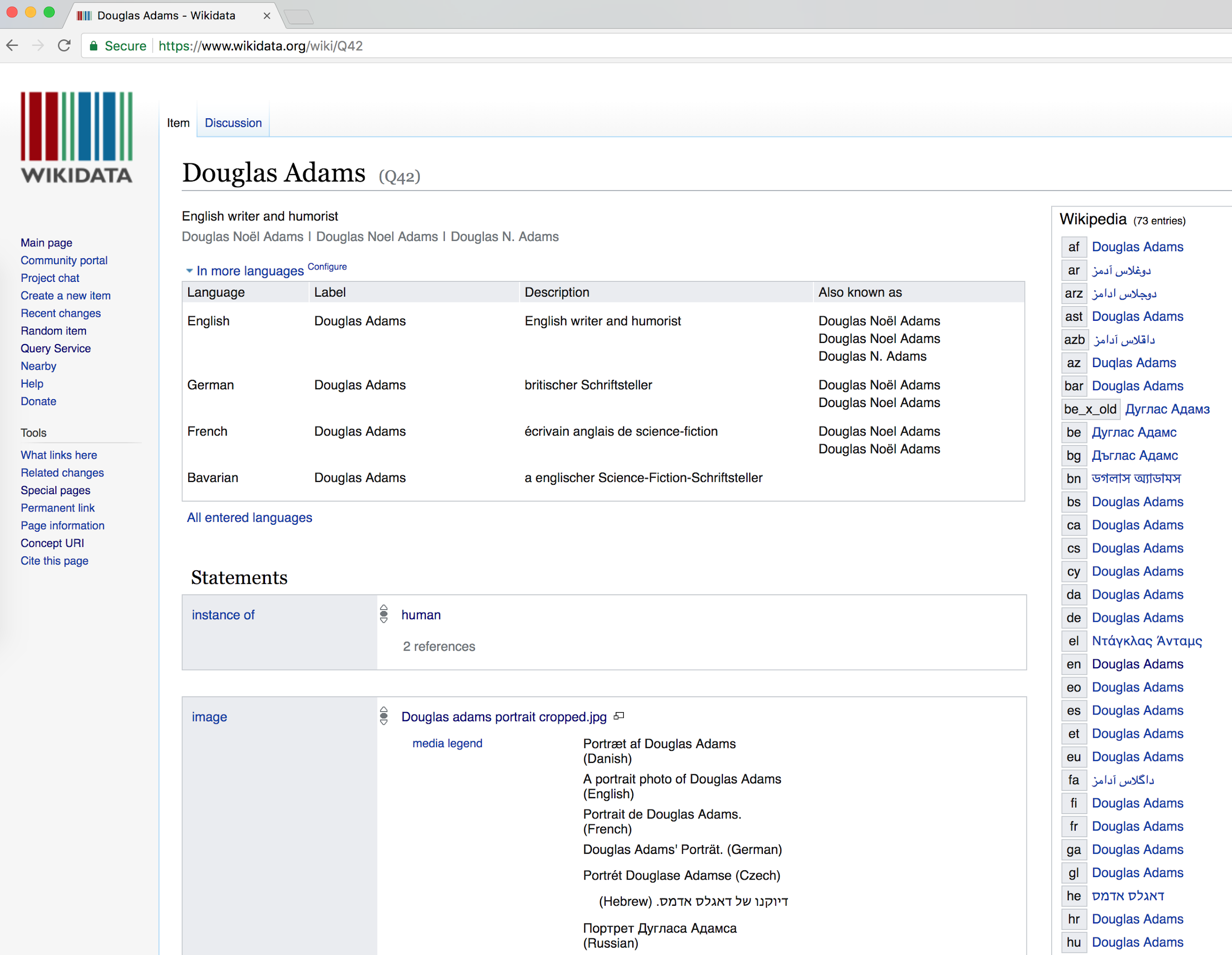
Эти страницы сущностей являются очень формальными и не самыми красивыми для чтения о жизни человека, но они содержат очень ценную информацию, описывая, что это за сущность и какие у нее отношения с другими сущностями.
Такие данные предназначены для использования другими службами. Например, информационные поля в правой части статей Википедии в основном дополнены информацией викиданных.
Некоторые люди создали инструменты для визуализации таких данных:

Как вы могли бы использовать структурированные данные из викиданных для своего собственного проекта?
Вы создали сайт для своего международного книжного клуба. Он поставляется с базой знаний, которая поддерживает уже 42 языка. Хотя управление контентом для авторов и книг довольно просто с Contentful, вы понимаете, что локализация иногда бывает болезненной, потому что вам трудно понять, как переводятся имена каждого человека.
Не паникуйте!
Вашему другу приходит идея создать расширение пользовательского интерфейса для Contentful, где вы можете просматривать викиданные и автоматически заполнять поля перевода имен и других общих свойств. Она даже разработала первый прототип для вас:
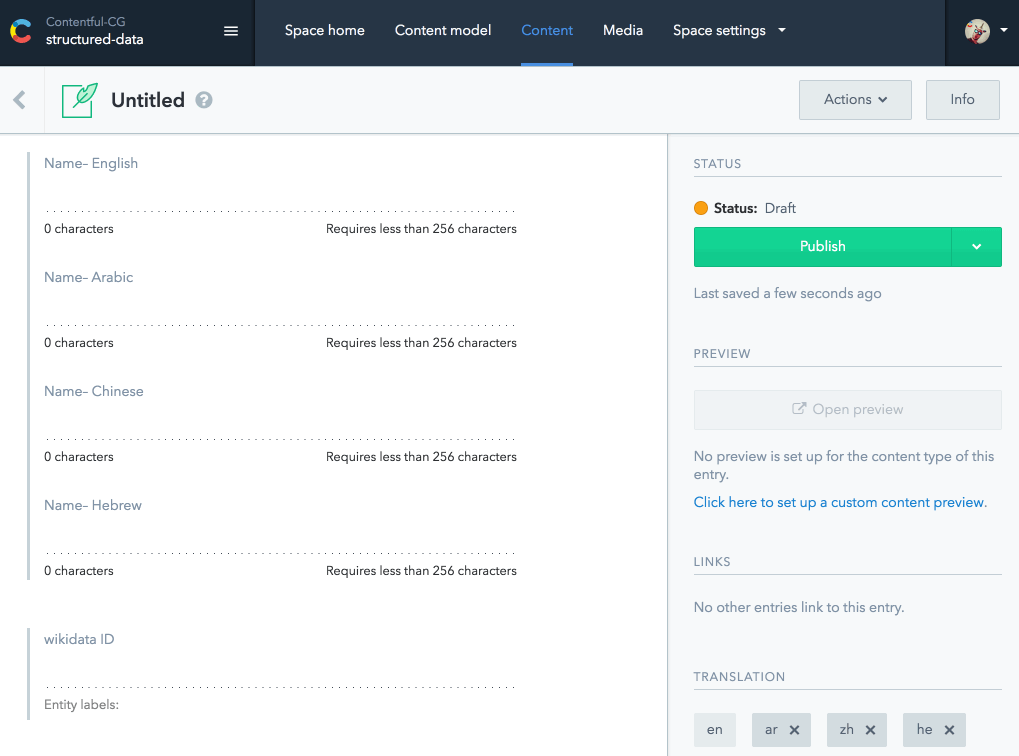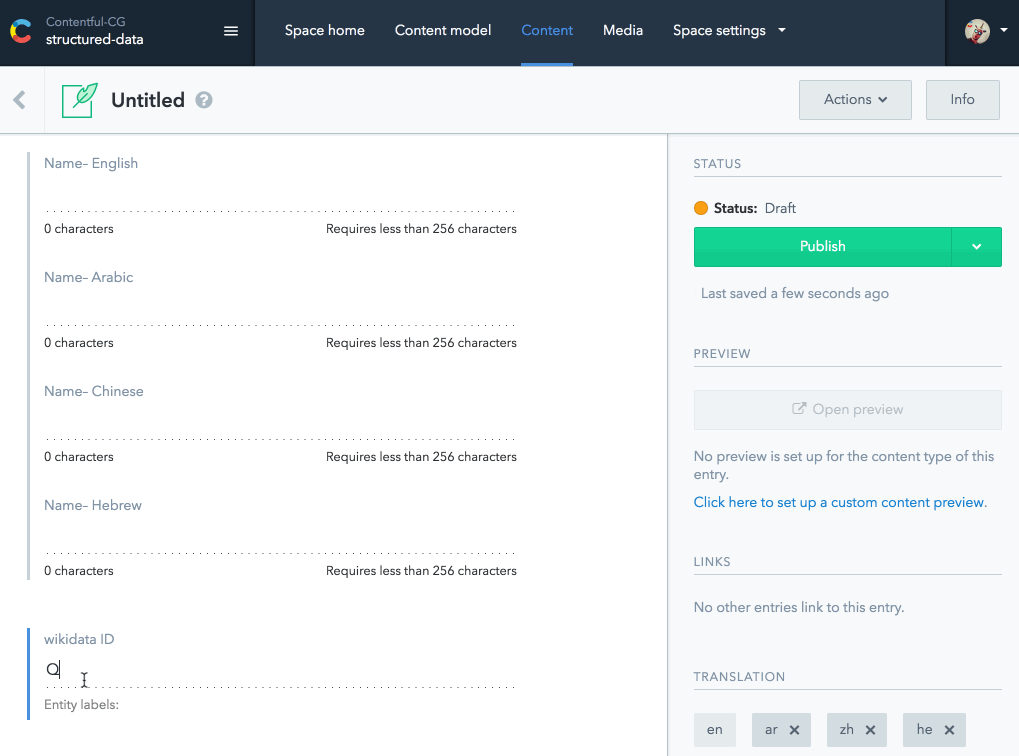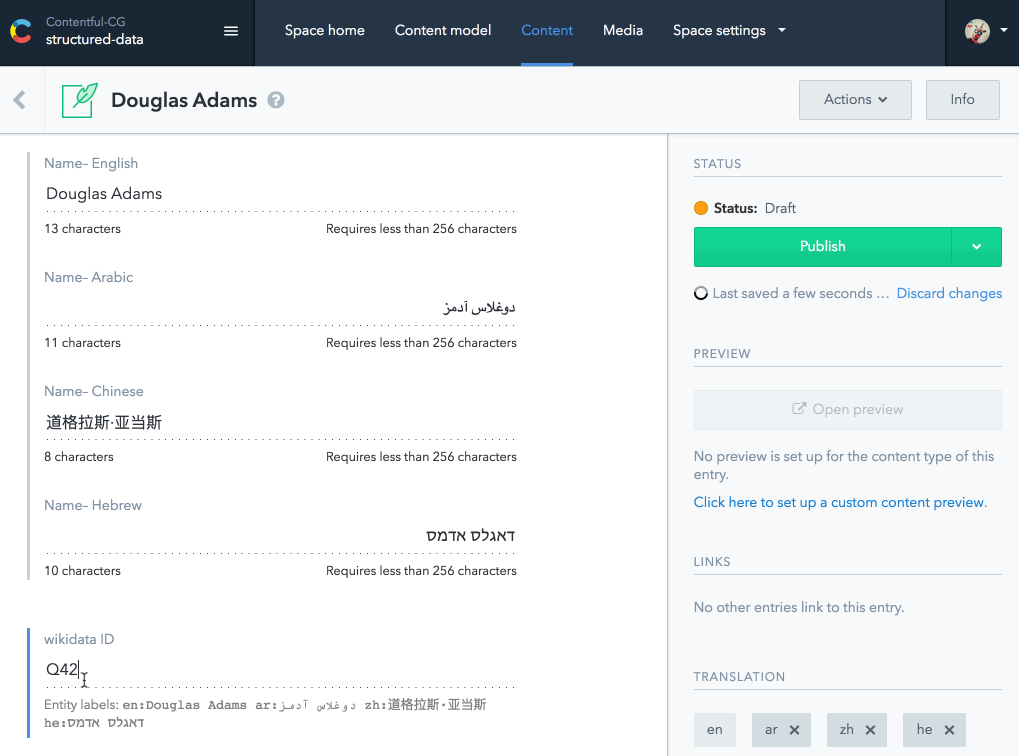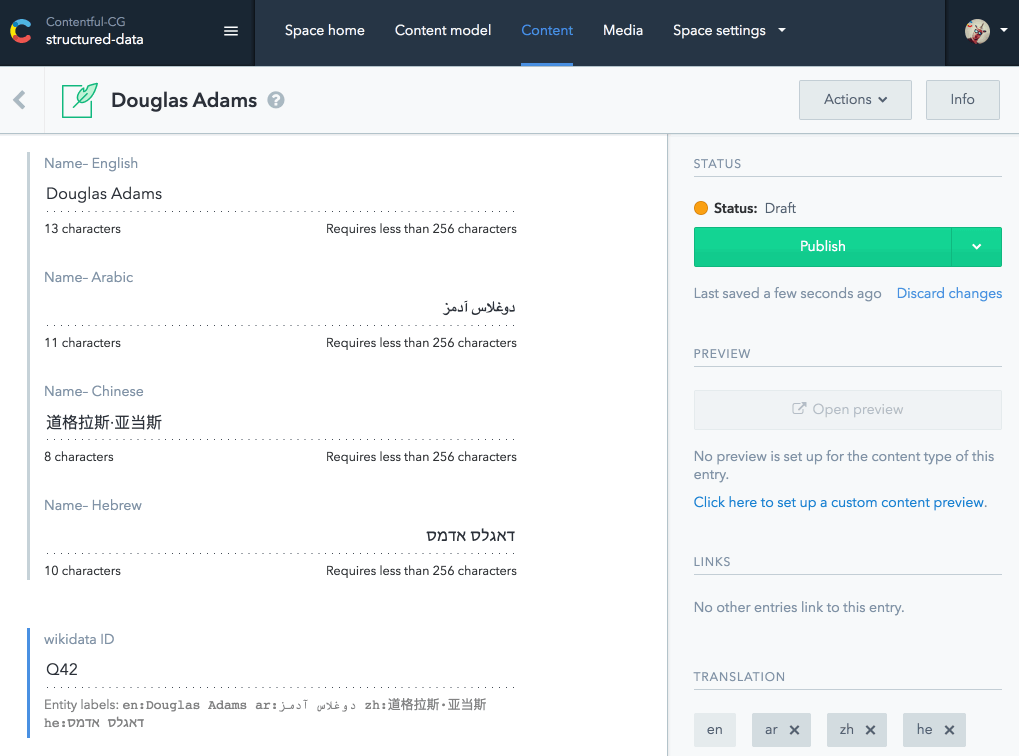
Содержательное расширение пользовательского интерфейса с wikidata.org
Вам это очень нравится, и вы начинаете думать о том, как автоматизировать множество других шагов. Например, расширение может извлечь все известные книги и создать черновики для каждой из них и связать их с авторской записью. Так как викиданные также предоставляют ссылки на другие сервисы Викимедиа, вы можете хранить их вместе со своими статьями базы знаний. Вы интегрируете множество ссылок на другие сайты и, возможно, хотите создать своего рода окно предварительного просмотра, похожее на Twitter Cards.
С хорошо поддерживаемыми структурированными данными возможности безграничны. Так что выходите, исследуйте и создавайте потрясающие вещи.
Так долго и спасибо за все рыбы! 🐟
Там теперь записанная версия этого сообщения в блоге:
Похожие
Руководство по жизни после Google ReaderНажмите на эту кнопку, а затем, после нескольких щелчков, News Blur перенесет ваши каналы перед тем, как Google Reader умрет. После этого NewsBlur работает как более симпатичная, более современная версия Google Reader 1.0. (Конечно, у сайта есть некоторые проблемы с подключением Kaspersky AdCleaner: Анти-Баннер для iOS
Обновление: приложение, описанное в этом посте, больше не поддерживается. Пользователи Kaspersky Internet Security и Kaspersky Total Security знакомы с Анти-Баннером, удобным компонентом, который блокирует надоедливую рекламу на веб-сайтах и в программных интерфейсах. Рекламные блоки действительно полезны в наши дни. Их использование позволяет быстрее открывать веб-сайты, делает веб-страницы Свадебный макияж Меган Маркл вызвал много споров. Для нас это сигнал, что пора меняться! Возможно...
Свадебный макияж Меган Маркл вызвал много споров. Для нас это сигнал, что пора меняться! Возможно, что больше из нас будет выглядеть как герцогиня Сассексская, а не как сестры Кардашьян. Если бы мы собирали Как смотреть видео из Instagram в браузере
... вы проводите много времени в Instagram, вы, несомненно, встретите живое видео. Если вы предпочитаете смотреть живое видео на своем компьютере во время его трансляции, вход в вашу учетную запись Instagram в браузере не поможет. Вместо этого вам понадобится расширение Chrome для просмотра живого видео из Instagram в вашем браузере. Вам понадобится расширение Chrome IG Story [больше не доступно], чтобы просматривать живые видео из аккаунтов Instagram, на которые вы подписаны. Тестовая страница для HTTP-сервера Apache в Red Hat Enterprise Linux
Если вы являетесь представителем общественности: Тот факт, что вы видите эту страницу, указывает на то, что на сайте, который вы только что посетили, либо возникли проблемы, либо он находится на плановом обслуживании. Если вы хотите, чтобы администраторы этого веб-сайта знали, что вы видели эту страницу вместо ожидаемой, отправьте им электронное письмо. Как правило, почта, отправляемая на имя «веб-мастер» и направляемая на домен сайта, должна доходить до соответствующего Как уменьшить проблемы с перегревом на ПК с Windows?
Когда компьютер перегревается, это может вызвать много проблем с внутренней работой компьютера, как центрального процессора ( ЦПУ ) перегревание может привести к значительным проблемам в работе. Есть много способов исправить эту относительно распространенную проблему и предотвратить перегрев, чтобы она не вызывала обострения замораживания и других неожиданных сбоев, которые могут привести к потере Как сделать C ++ более дружественным в реальном времени
Для разработчиков, заинтересованных в использовании C ++ в системах реального времени, есть как хорошие, так и плохие новости. Во-первых, плохие новости: проблемы, на которые ссылаются Гуч и Торвальдс, все еще актуальны и сегодня. Ричард Э. Гуч : «Я лично считаю, что C ++ имеет свои преимущества и облегчает объектно-ориентированное программирование. Тем не менее, это более сложный язык Как правильно разместить страницу?
Было бы сложно посчитать количество вопросов относительно метода позиционирования, которое выпадает на наших клиентов. Ничего странного - ведь сайт является основой работы компании в виртуальном пространстве . Поэтому важно принять правильное решение, связанное с подбором лиц, ответственных за его позиционирование . Тем более, что мы можем встретиться с различными нечестными приемами, которые вызывают доверие у профессионалов SEO. Безопасное позиционирование Биткойн (BTC) - что такое криптовалюта Биткойн и обмен BTC?
... вызваны глобальным ростом интереса к криптовалютам. Вы можете спросить себя, что такое криптовалюты и как вы можете принять участие в технологическом буме без специальных знаний в области ИТ? Основные факты о биткойнах (BTC) и других криптовалютах Биткойн - это форма цифровой валюты, созданная и хранящаяся в электронном виде. Созданная в 6 сигналов, которые вам нужны SEO
... какой-то момент может оказаться, что потребуется экспертная поддержка. Знаете ли вы причины, по которым вам следует делегировать действия, связанные с позиционированием профессионалов? Знаете ли вы, когда вашей компании нужно пользоваться услугами агентства SEO? Самостоятельные действия не приносят ожидаемых выгод Самая очевидная причина, которая указывает на необходимость наладить сотрудничество с SEO-агентством, - это отсутствие последствий самостоятельно CB радиочастоты и каналы
Как появилось CB Radio? Радио Citizens Band (CB) восходит к 1940-м годам. Федеральная комиссия по связи (FCC), которая все еще регулирует CB, взяла полосы от канала 11 Службы радиолюбителей (aka Ham), чтобы сформировать полосу (460-470 мегагерц UHF) для личного и делового общения, а также для управления модельными самолетами. , Деловое
Комментарии
Почему бы сразу не нарисовать маленького Ван Гога?Почему бы сразу не нарисовать маленького Ван Гога? с палец краска и один Живопись фартук Одетые, дети уже заняты днем, и вы даже можете бежать. Если вы чувствуете, что футболки и другие ткани с Finger текстильная краска aufhübschen. Рулоны туалетной бумаги: хотите верьте, хотите нет, это нечто большее, чем вы думаете. Например, ты можешь Является ли предположение, что текущая цена биткойна слишком высока, и / или предположение, что ежегодное повышение цены на 10% слишком оптимистично?
Является ли предположение, что текущая цена биткойна слишком высока, и / или предположение, что ежегодное повышение цены на 10% слишком оптимистично? Мы оставляем выводы для читателей. Имейте в виду, что, изменяя предположения о количестве транзакций в блоке, мы можем получить разные результаты. Кроме того, Биткойн отличает много других цен, помимо стоимости. Это также время для подтверждения транзакции, которая сейчас намного короче, чем в банковской системе, а также конфиденциальность, которая Что именно он предлагает?
Что именно он предлагает? статистика сайта; более легкий обмен контентом в социальных сетях; резервное копирование и другие страницы безопасности; дополнительные возможности форматирования текста; контактные формы. Некоторые опции доступны в платной версии плагина, однако предлагаемых бесплатных опций вполне достаточно . Akismet Какие компромиссы вы должны сделать?
Какие компромиссы вы должны сделать? Работайте с внутренними заинтересованными сторонами - иногда вам нужно доказать, что ваши бюджеты - это инвестиции, которые обеспечат положительный возврат инвестиций для бизнеса. Вам нужны люди, которые поддерживают ваши усилия. Планируйте свои кампании в социальных сетях. Когда ваша стратегия и бюджет в социальных сетях будут приняты, вы сможете приступить к планированию этапа выполнения. Какими будут Хотите получить максимальную отдачу от своего нового MacBook, iMac или другого компьютера Apple?
Хотите получить максимальную отдачу от своего нового MacBook, iMac или другого компьютера Apple? Независимо от того, является ли это вашим первым ноутбуком или вы только что перешли с Windows, о вашем новом Mac вы должны знать несколько вещей, таких как основные сочетания клавиш или как использовать различные функции, которые может предложить macOS. Узнайте больше о том, что ваш компьютер Mac может сделать для вас в Intego New Mac User Center: Что если он дважды вызывает hasNext ()?
Что если он дважды вызывает hasNext ()?) Кроме того, протокол с двумя методами обычно требует достаточного количества состояний, таких как просмотр одного элемента вперед (и отслеживание того, вы уже заглянули вперед). Вместе эти требования в совокупности увеличивают затраты на доступ к элементам. Наличие лямбда-выражений в языке позволяет Spliterator использовать подход к доступу к элементам, который, как правило, более эффективен и легче кодируется правильно. У Spliterator есть два метода Знаете ли вы, что принесет вам?
Знаете ли вы, что принесет вам? 😉 основное фото: pixabay Но что стоит за этой впечатляющей репутацией?
Но что стоит за этой впечатляющей репутацией? Мы обнаружили некоторые интересные факты, которые вы должны знать. Все об антивирусе: Вирусный сканер для смартфонов: абсолютная чушь? Стоит ли устанавливать антивирусное ПО на свой смартфон? Это действительно Вы когда-нибудь пытались добавить кликабельную ссылку к своим видео на YouTube, но обнаружили, что просто нет способа сделать это?
Вы когда-нибудь пытались добавить кликабельную ссылку к своим видео на YouTube, но обнаружили, что просто нет способа сделать это? Ну, на самом деле есть два способа, методы, которые остались скрытыми ... Прочитайте больше на другие сайты и видео, подчеркивая интерактивный аспект Интернета. И тогда у нас есть документы. Истории, отчеты, возможно, информационные бюллетени и Итак, что если ваше приложение хочет выполнить более четырех операций 256-битного FPU?
Итак, что если ваше приложение хочет выполнить более четырех операций 256-битного FPU? Из-за потери дополнительного ядра FPU отсутствие возможности дальнейшего разделения рабочей нагрузки будет указывать на потенциальную потерю производительности. Как пользователь Windows 7 или Windows Vista, вы уже отключили боковую панель и гаджеты?
Как пользователь Windows 7 или Windows Vista, вы уже отключили боковую панель и гаджеты?
Какие книги написал автор Дуглас Адамс?
Как вы могли бы использовать структурированные данные из викиданных для своего собственного проекта?
Какие книги написал автор Дуглас Адамс?
И, честно говоря, вы, скорее всего, нажмете на сообщение в блоге, когда у него хорошее изображение обложки и строка описания, не так ли?
Вы можете спросить себя, что такое криптовалюты и как вы можете принять участие в технологическом буме без специальных знаний в области ИТ?
Знаете ли вы причины, по которым вам следует делегировать действия, связанные с позиционированием профессионалов?
Знаете ли вы, когда вашей компании нужно пользоваться услугами агентства SEO?
Почему бы сразу не нарисовать маленького Ван Гога?
Является ли предположение, что текущая цена биткойна слишком высока, и / или предположение, что ежегодное повышение цены на 10% слишком оптимистично?
Что именно он предлагает?